|
Поиск по сайту: |
|
По базе: |
| Главная страница > Компоненты > Atmel > Микроконтроллеры | |||||||||
|
|
||||||||
Инновационные способы обработкиГруппа разработчиков AVR компании Atmel достигла исключительной производительной ядра AVR32 за счет ряда особенностей улучшающих эффективность машинного цикла, в т.ч.:
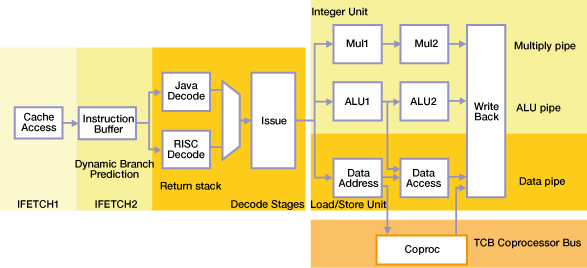
Кроме того, при разработке архитектуры ядра AVR32 минимизировалось потребление, как в активном режиме, так и в дежурном (ток утечки). Арифметические операции с указателями минимизируют циклы ввода-вывода Около 30% процессорных циклов тратится не на выполнение операций, а на выполнение инструкций ввода-вывода. У ядра AVR32 сокращено требуемое количество инструкций ввода-вывода за счет объединения инструкций ввода-вывода байта (8 бит), полуслова (16 бит), слова (32 бита) и двойного слова (64 бита) с различными арифметическими операциями над указателями. Такие инструкции повышают эффективность доступа к таблицам, структурам данных и произвольным данным за наименьшее количество циклов. Примером такой инструкции является "загрузка с извлечением указателя". К наиболее популярным криптографических алгоритмам относятся такие алгоритмы блочного шифра, как Blowfish, Triple-DES и Rijndael. Во всех этих алгоритмах используются специальные операции матричной адресации, на выполнение которых прочие микропроцессоры требуют длинной последовательности инструкций. Набор инструкций AVR32 поддерживает данные алгоритмы новыми инструкциями загрузки, которые загружают слово с извлечением указателя. Ниже приведен пример такой операции: result = pointer0[offset0 >> 24] ^ pointer1[(offset1 >> 16) & 0xff] ^ pointer2[(offset2 >> 8) & 0xff] ^ pointer3[offset3 & 0xff]; В данной операции доминируют четыре операции доступа к памяти, которые извлекают один из четырех байт в 32-разрядном слове, дополняют его нулями и прибавляют к базовому указателю. В результате этой операции генерируется адрес памяти, к которому может быть осуществлен доступ. Обычные процессорные архитектуры требуют 14 тактов для выполнения данной операции, а AVR32 может выполнить эту инструкцию всего лишь за 7 тактов синхронизации. AVR32 может выполнить загрузку с извлеченным индексом со всеми 4 доступами к памяти за четыре такта при запоминании всех четырех смещений в одном регистре. За счет уменьшения выполняемого количества инструкций ввода-вывода ядро AVR32 увеличивает производительность машинного цикла. Всего, ядро AVR32 поддерживает 28 инструкций, которые повышают эффективность операций ввода-вывода. Набор инструкций с одним потоком команд и множеством потоков данных (SIMD) SIMD -инструкции в архитектуре AVR32 могут учетверить производительность некоторых алгоритмов цифровой обработки сигналов, которые требуют выполнения однотипных операций над потоком данных (например, оценка параметров движения при MPEG-декодировании). Вычисление 8-разрядной суммы абсолютных отклонений выполняется путем загрузки четырех 8-разрядных пикселей из памяти с помощью одной операции загрузки, затем выполнением сжатого вычитания беззнаковых байт с насыщением, сложением старших и младших пар сжатых байт и распаковкой их в сжатые полуслова. Для получения результирующего значения полуслова складываются вместе. Многоконвейерная архитектура повышает производительность машинного цикла ЦПУ AVR32 AP содержит 7-ступенчатый конвейер с 3 подконвейерами (умножение/умножение-накопление, ввод-вывод и АЛУ), который позволяет выполнять арифметические операции независимо от исполняемых данных, вне порядка и параллельно. Традиционные процессорные архитектуры содержат один конвейер, который приостанавливает выполнение кода до завершения выполнения каждой инструкции. За счет этого теряются существенные вычислительные ресурсы при выполнении многоцикловых инструкций. Логика работы конвейера AVR32 AP позволяет выполнять одновременно несвязанные инструкции с помощью доступных конвейерных ресурсов. Выполнение вне порядка позволяет повысить производительность машинного цикла. Логика детекции опасности определяет и удерживает связанные инструкции в начале конвейера до завершения операции, от которой они зависят.
Продвижение данных по конвейеру AVR32 исключает множество циклов, используемых для записи и чтения регистровых файлов за счет продвижения данных между конвейерными ступенями. Инструкции, которые закончили свое выполнение перед ступенью обратной записи незамедлительно передают данные в начало конвейера для выполнения инструкций, ожидающих их результат. За счет минимизации числа регистровых доступов сокращается как количество циклов, так и потребляемая мощность. Аппаратный прогноз переходов Несмотря на то, что многоконвейерная архитектура повышает производительность, выполнение операций переходов по программе снижает быстродействие. Проблема потерь времени на переходы особенно ощутима при построении небольших вложенных циклов. Для адресации данной проблемы в состав конвейера AVR32 входит логика предсказания перехода, которая может точно предсказать результат выполнения всех инструкций изменения программного потока. Затем, переход "прикрепляется" к целевой инструкции и выполняется вместе с ней, что исключает какие-либо задержки на его выполнение. Исключительная плотность кода улучшает эффективность использования кэш-памяти Набор инструкций AVR32 был подвержен обширному анализу и очистке с помощью прогрессивной компиляционной технологии. В результате, использование программного пакета EEMBC позволило повысить плотность кода от 5% до 50% по сравнению с конкурирующими ядрами. Уплотнение кода позволяет большее количество инструкций разместить в процессорном кэше, тем самым, увеличивая эффективность использования кэш-памяти и общую производительность процессора за цикл. Набор инструкций поддерживает перспективные операционные системы Основные архитектуры ЦПУ разрабатывались до появления операционных систем, которые широко используются в настоящее время. Как результат, ядра ЦПУ тратят время на вызов операционной системы или внешних приложений. При разработке архитектуры AVR32 изначально учитывалось использование операционных систем, в т.ч. операционная система Linux. Примерами такой поддержки являются инструкции вызова приложения (ACALL) и системного вызова (SCALL), которая вызывает процедуру операционной системы. Расширенный блок управления памятью и режимы защиты ядра AVR32 также поддерживают современные операционные системы, как, например, Linux. Снижение тактовой частоты обеспечивает сверхмалую потребляемую мощность Превосходная производительность ядра AVR32 уменьшает требуемое количество циклов и, следовательно, уменьшает потребляемую мощность. Кроме того, ядро AVR32 разработано для минимизации потребления мощности при тактировании любой частотой за счет размещения данных максимально близко к ЦПУ и минимизации избыточных передвижений данных по шине, на что затрачивается часть мощности. Например, в более старых архитектурах микроконтроллеров копируется адреса возврата процедуры в стек, что приводит к неоправданной потери энергии. У AVR32 исключена такая потребность за счет включения регистра связи в регистровый файл. Другой энергосбергающей особенностью является запоминание регистра статуса и адресов возврата из прерываний и исключений в системных регистрах без передвижения данных в стек и обратно.
Главная - Микросхемы - DOC - ЖКИ - Источники питания - Электромеханика - Интерфейсы - Программы - Применения - Статьи |
||||||||