4.2.3. Прямой доступ к памяти
Передача данных между УВВ и внутренним статическим ОЗУ может осуществляться, как при участии ЦПУ Cortex, так и автоматически под управлением встроенного блока ПДП. Блок ПДП микроконтроллеров STM32 имеет семь раздельно настраиваемых каналов, позволяющие автоматически передавать данных из памяти в память, из УВВ в память, из памяти в УВВ и из УВВ в УВВ. Передача память-память выполняется с максимально-возможным для канала ПДП быстродействием. Если же в передаче данных участвует УВВ, то блок ПДП оказывается под его управлением и передача данных будет происходить по запросу УВВ в любом из направлений. Помимо передачи блоков данных, каждый блок ПДП может непрерывно передавать данные в кольцевой буфер. Поскольку встроенные коммуникационные УВВ вообще не оснащены буферами FIFO, то каналы ПДП могут использоваться для передачи данных между УВВ и буферами в статическом ОЗУ. Блок ПДП был специально разработан под особенности МК STM32 и оптимизирован под частую передачу коротких потоков данных, что типично для микроконтроллерных применений.
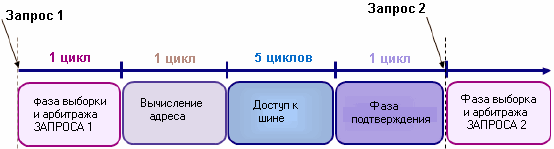
Каждая передача память-память состоит из четырех фаз. Фаза доступа к шине длится 5 циклов, а все остальные - 1 цикл
Каждая передача, осуществляемая блоком ПДП, состоит из четырех фаз: фаза выборки и арбитража, фаза вычисления адреса, фаза доступа к шине и фаза подтверждения. Все фазы, кроме фазы доступа к шине, длятся 1 цикл. Фаза доступа к шине (имеет место всякий раз, когда передаются реальные данные) длится 3 цикла и необходима для передачи слова данных. Чтобы блок ПДП и ЦПУ Cortex могли работать совместно, их активность чередуется, т.о. ПДП не блокирует работу ЦПУ и наоборот. Прежде чем перейти к рассмотрению механизма чередования, необходимо упомянуть о влиянии приоритетов на передачу между различными каналами ПДП. Каждому из каналов ПДП программным способом назначается один из четырех уровней приоритета. На фазе арбитража доступ к шине получает канал с наивысшим уровнем приоритета. Если запрос на передачу отправили два блока ПДП и оба имеют одинаковый уровень приоритета, то доступ к шине получит канал с наименьшим порядковым номером.
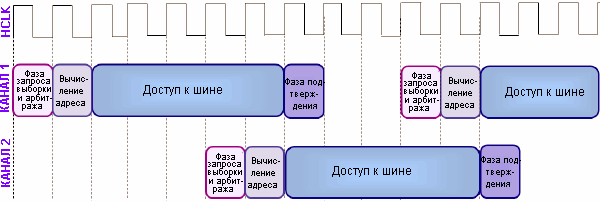
Блок ПДП разработан для быстрой передачи небольших потоков данных. Потребность в такой передаче типична для небольших встраиваемых систем. Блок ПДП занимает шину только на фазе доступа к шине
Блок ПДП может выполнять фазу арбитража и вычисления адреса, даже если другой канала ПДП находится на фазе доступа к шине. Как только активный канал закончит передачу данных по внутренней шине, очередной канал ПДП уже будет готов к передаче и незамедлительно приступит к ее осуществлению, когда текущая передача завершится выполнением фазы подтверждения. Таким образом, каналы ПДП позволяют не только передавать данные быстрее, чем ЦПУ. Их работа еще и тщательно чередуется, а шина занимается только на время фактической передачи данных.
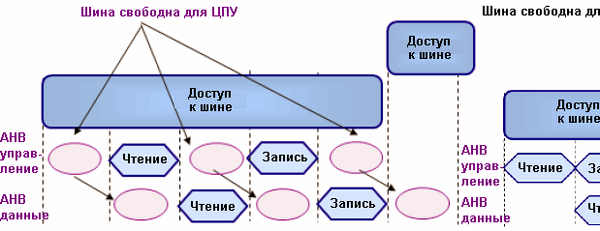
На каждой фазе доступа к шине три цикла свободны для ЦПУ. При передачах типа память-память этим гарантируется, что ЦПУ будет выделено минимум 60% шины, даже если ПДП выполняется непрерывно. Помните, что это касается только передачи данных, а выборку инструкций ЦПУ Cortex осуществляет по отдельной шине инструкций I-code
В передачах типа память-память каждый из каналов ПДП будет занимать шину данных только во время фазы доступа к шине, при этом, на передачу каждого слова данных будет затрачиваться 5 циклов. Из них один цикл - для чтения и еще один - для записи, причем данные циклы чередуются холостыми циклами, во время которых шина освобождается для ЦПУ Cortex. Это означает, что блоки ПДП будут использовать не более 40% от пропускной способности шины данных даже во время непрерывной передачи данных на максимальной скорости. При передачах типа УВВ-УВВ и УВВ-память ситуациия несколько более сложная.
Передачи по шине AHB выполняются за два цикла на частоте синхронизации этой шины, а передачи по шине APB требуют для выполнения 2 циклов на частоте синхронизации этой шины и еще 2 цикла на частоте синхронизации шины AHB. Каждая передача блока ПДП состоит из двух периодов передачи по шине и свободного цикла. Например, передача из модуля SPI в статическое ОЗУ состоит из передачи из модуля SPI, из передачи в статическое ОЗУ и из одного свободного цикла. Следовательно,
Передача из SPI в стат. ОЗУ = Передача SPI (APB) + передача стат. ОЗУ (AHB) + свободный цикл (AHB) = (2 цикла APB + 2 цикла AHB) + 2 цикла AHB + 1 цикл AHB = 2 цикла APB + 5 циклов AHB
Помните, что все это касается только передачи данных, т.к. все выборку инструкций ЦПУ Cortex осуществляет по отдельной шине I-Bus.

У блока ПДП имеется семь каналов. Каждый канал является полностью ортогональным
Очередной хорошей новостью, касающейся блока ПДП, является то, что он чрезвычайно прост в использовании. Вначале необходимо включить синхронизацию блока ПДП и вывести его из состояния сброса. Это выполняется через регистр разрешения синхронизации AHB в блоке управления сбросом и синхронизацией.
RCC->AHBENR |= 0x00000001; // разрешение синхронизации блока ПДП
|
После подачи питания на блок ПДП. каждый из его каналов управляется через четыре регистра. В двух регистрах хранятся адреса источника и получателя (регистр УВВ и ячейка памяти). Данные о размере передачи хранятся в регистре "количества данных", а общие характеристики ПДП-передачи задаются через регистр конфигурации.

Каждый из каналов ПДП управляется через четыре регистра и поддерживает генерацию трех прерываний: по завершении, половинном завершении и ошибках передачи
Каждому из каналов ПДП можно назначить четыре уровня приоритета: "очень высокий", "высокий", "средний" и "низкий". Размера передаваемого слова задается раздельно для памяти и УВВ. Например, мы можем передать 32-битное слово в канал ПДП (3 цикла) из памяти, а затем передать четыре 8-битных слова в регистр данных УАПП (всего потребуется 35 циклов вместо 64, если бы все данные передавали 8-битными порциями.) Также имеется возможность инкрементирования адресов памяти и УВВ. Потребность в этом может возникнуть, например, при периодической передаче данных из регистра результата АЦП в массив памяти для дальнейшей обработки. Чтобы задать в каком из направлений, память - УВВ или УВВ - память, необходимо передавать данные, предусмотрен бит направления передачи. При передачах типа память-память необходимо установить бит 14 для передачи данных между двумя буферами в статическом ОЗУ на максимально-возможной скорости. Использовать каналы ПДП можно, как в режиме опроса, так и с использованием прерываний по завершению, половинному завершению и при ошибках передачи. Наконец, после завершения настройки ПДП-передачи, необходимо установить бит разрешения работы канала и передача начнется. Передачу память-память можно выполнить с помощью следующего кода программы:
DMA_Channel1->CCR = 0x00007AC0; //настройка передачи память-память
DMA_Channel1->CPAR = (unsigned int)src_arry; //выбор источника и получателя
DMA_Channel1->CMAR = (unsigned int)arry_dest;
DMA_Channel1->CNDTR = 0x000A; //задание размера передачи
TIM2->CR1 = 0x00000001; //запуск таймера
DMA_Channel1->CCR |= 0x00000001; //запуск ПДП-передачи
while(!(DMA->ISR & 0x0000001)) //ожидание завершения передачи
{;}
TIM2->CR1 = 0; //остановка таймера
TIM2->CNT = 0; //сброс счетчика
TIM2->CR1 = 1; //перезапуск таймера
for(index = 0;index <0xA;index++) //повторяющиеся операции, выполняемые ЦПУ
{
arry_dest[index] = arry_src[index];
}
TIM2->CR1 = 0; //остановка таймера
}
|

В данном коде программы демонстрируется простая передача память-память. Счет количества циклов выполняется внутренним таймером
В приведенном выше коде выполняется передача 10 слов данных между двумя массивами в статическом ОЗУ: вначале с использованием ПДП, а затем с использованием только ЦПУ Cortex. В каждом из этих случаев, перед началом передачи запускается таймер и останавливается по завершении передачи. В данном примера блок ПДП выполняет передачу за 220 циклов, ЦПУ - за 536.
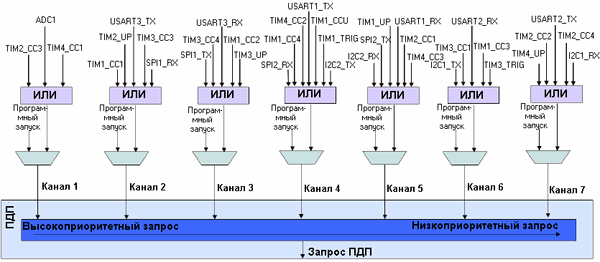
Каждое УВВ, которое поддерживает ПДП, связано с конкретным каналом. После разрешения работы, УВВ становится контроллером потока для ПДП-передачи. Благодаря этому, прием и передача данных выполняются без какого-либо участия ЦПУ
Несмотря на то, что передачи типа память-память выгодно использовать для инициализации областей памяти, а также для передачи блоков данных, большую часть времени каналы ПДП будут использоваться для перемещения данных между памятью и различными УВВ. В связи с этим, каждый из каналов ПДП связан с определенной группой УВВ. Вначале, необходимо инициализировать УВВ и разрешить поддержку им ПДП. Затем, нужно настроить соответствующий канал ПДП для передачи данных по запросу поддерживаемого им УВВ. Например, более подробно рассматриваемый далее АЦП по завершении каждого преобразования помещает 10-битный результат в регистр результата преобразования. Если ПДП не использовать, то ЦПУ будет вынужден периодически обрабатывать прерывания по завершению преобразования АЦП. Если же использовать ПДП, то по окончании каждого преобразования АЦП будет генерировать запрос на ПДП-передачу, а блок ПДП передаст результат преобразования АЦП в статическое ОЗУ по инкрементированному адресу. При таком подходе участие ЦПУ потребуется только для обработки подготовленного массива данных после завершения передачи последней выборки.
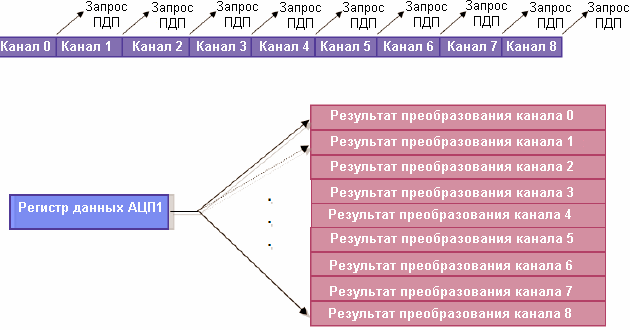
УВВ микроконтроллеров STM32 не содержат каких-либо буферов памяти. Использование ПДП в его кольцевом режиме позволяет использовать любой объем памяти в качестве буфера УВВ. Используя прерывания по половинному и полному завершению передачи, можно организовать двойной кольцевой буфер
Чтобы этот процесс был более эффективен, можно активизировать поддержку кольцевого буфера, что позволит АЦП непрерывно записывать данные в этот буфер. Затем, используя прерывания по половинному и полному завершению ПДП передачи, можно создать двойной буфер. После заполнения первой половины буфера генерируется прерывание, которое позволяет перейти к обработке накопленных данных, а, при этом, новые данные будут продолжать накапливаться во второй половине буфера. Аналогичным образом, после заполнения второй части буфера, можно перейти к обработке данных, при этом, ПДП начнет перезаполнение буфера новыми данными. Такой же механизм работы ПДП можно использовать и совместно с другими УВВ. Единственно, важно обратить внимание, что у коммуникационных УВВ реализованы раздельные каналы ПДП приема и передачи. Например, модуль SPI может одновременно передавать данные в обоих направлениях.
|


